
Abstract
The demand for local high quality text to speech synthesis has grown significantly in recent years. However many of the most advanced models require expensive hardware and massive amounts of video memory. This technical paper investigates the performance of several popular text to speech engines on a budget friendly system. The objective is to determine which model provides the best balance of speed and resource efficiency for a low power laptop equipped with a modest graphics card. Based on quantitative benchmark data Kokoro 82M emerges as the definitive solution for local deployment on restricted hardware.
System Specifications and Methodology
The testing environment was designed to represent a typical low power consumer laptop. Seven engines were evaluated comprising a mix of cloud APIs local artificial intelligence models and operating system level speech subsystems.
Hardware Specifications
- Operating System Windows 11 Pro
- Processor AMD Ryzen 5 3500H
- System Memory 16 GB DDR4
- Graphics Processing Unit NVIDIA GTX 1650 4 GB VRAM
- Environment Python 3.11
The benchmark evaluated generation time and hardware resource consumption across short medium and long text inputs. Tests lacking complete data across all platforms such as subjective naturalness scores and partial edge case pronunciation evaluations were systematically excluded from this analysis. The focus remains strictly on processing speed and resource utilization.
Test Methodology and Procedures
To ensure a fair and comprehensive evaluation each engine was subjected to a standardized testing protocol. The methodology was designed to measure generation speed and resource utilization under consistent conditions.
Test Procedure
Each engine synthesized a standardized set of short medium and long text inputs.
Every run was timed from the initial synthesis call to the completion of the file writing process to capture the true wall clock time.
Hardware resource consumption including CPU RAM and GPU usage was sampled at peak levels during the synthesis process.
Output audio was generated for further qualitative evaluation although this paper focuses primarily on the hardware metrics.
All tests were executed three times and the results were averaged to eliminate variance and ensure statistical reliability.
Cold start times which include initial model loading into memory were recorded separately from the active generation times.
Test Inputs
The benchmark utilized a tiered text approach to evaluate performance scaling across different workload sizes.
Short Text
This input consists of exactly 64 characters.
"The quick brown fox jumps over the lazy dog near the river bank."
Medium Text
This input comprises approximately 482 characters.
"Artificial intelligence has transformed the way we interact with technology. From voice assistants that understand natural language to recommendation systems that predict our preferences AI is embedded in nearly every aspect of modern life. As these systems become more sophisticated the conversation around ethical AI development becomes increasingly important challenging researchers and developers to build transparent fair and accountable systems that benefit humanity as a whole."
Long Text
This comprehensive input contains approximately 1660 characters.
"The history of text to speech technology spans several decades beginning with rudimentary systems that could barely produce intelligible output. In the 1960s early synthesizers used formant based approaches generating mechanical sounding speech by manipulating frequency parameters. These systems were groundbreaking for their time but produced output that was clearly artificial and often difficult to understand.
The 1990s saw the rise of concatenative synthesis which stitched together pre recorded speech segments to create more natural sounding output. This approach significantly improved quality but required massive databases of recorded speech and often produced audible discontinuities at segment boundaries.
The deep learning revolution of the 2010s fundamentally changed the landscape. Neural network architectures like WaveNet Tacotron and VITS enabled the generation of speech that was nearly indistinguishable from human recordings. These models learned to capture the subtle nuances of prosody intonation and rhythm that make speech sound natural.
Today lightweight models like Piper and Kokoro bring high quality synthesis to consumer hardware while large models like Bark push the boundaries of expressiveness and multi speaker capability. Cloud services like Google TTS and Microsoft Edge TTS offer neural quality voices without local computational requirements.
The future promises even more exciting developments such as real time voice cloning emotion aware synthesis and multilingual models that seamlessly switch between languages within a single utterance. As the technology matures the line between synthesized and human speech continues to blur."
Edge Case Inputs
To evaluate model robustness various edge cases were tested.
Minimal input testing using "Hello world"
Abbreviations currency and dates using "Dr. Smith earned $1,200.50 on 01/15/2026."
Diacritics and Unicode characters handling via "The café résumé naïve coöperate"
Homograph disambiguation with "I read that they read the book."
Excessive punctuation handling testing "!!!??? ...Well well well..."
Emphasis and capitalization evaluated with "URGENT PLEASE RESPOND IMMEDIATELY"
Complex vocabulary testing using "The heterogeneous conglomerate utilized synergistic paradigms."
Empty string inputs to verify error and exception handling
Generation Time Results
Processing speed was measured in seconds from the initial synthesis call to file write completion. The results are divided into CPU and GPU execution modes depending on engine capabilities.
Table 1 CPU Mode Generation Times in Seconds
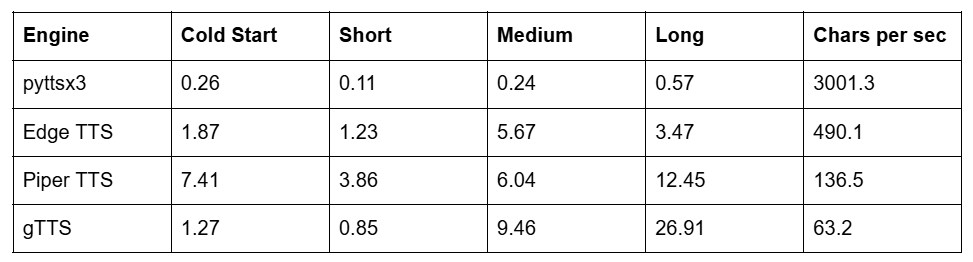
The traditional pyttsx3 engine was predictably the fastest due to its reliance on basic operating system resources. However its output suffers from severe robotic artifacts making it unsuitable for modern applications. Among cloud solutions Edge TTS vastly outperformed gTTS. Piper TTS demonstrated excellent CPU performance generating a long text passage in 12.45 seconds proving itself highly optimized for systems lacking dedicated graphics.
Table 2 GPU Mode Generation Times in Seconds
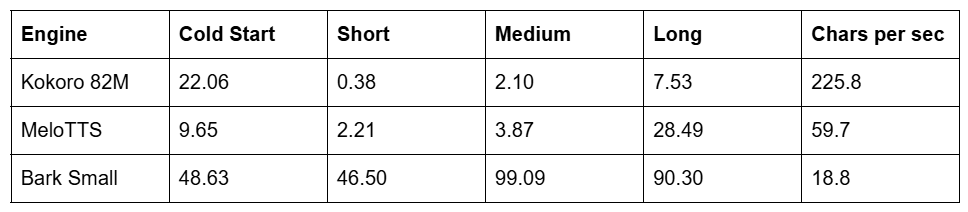
When utilizing the GTX 1650 GPU the results shifted dramatically. Bark proved completely unviable for low power hardware requiring 99 seconds to process a medium text. Kokoro 82M achieved a remarkable 225.8 characters per second processing a long text passage in a mere 7.53 seconds.
Resource Consumption and Hardware Constraints
Memory and processor utilization dictate whether an engine can run comfortably in the background without causing system instability. Peak usage was recorded during synthesis.
Table 3 Peak Resource Utilization
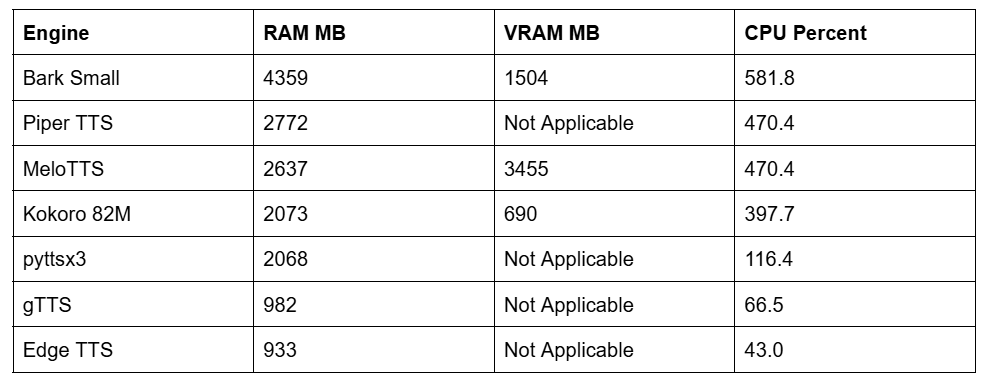
Bark is a massive resource hog overwhelming the system memory and processing cores. MeloTTS dangerously flirts with the 4 GB limit of the GTX 1650 by consuming nearly 3.4 GB of VRAM limiting the ability to run concurrent graphical applications. Kokoro 82M requires only 690 MB of VRAM and roughly 2 GB of system RAM offering an exceptionally low footprint for a neural model.
Conclusion
The quantitative benchmark data paints a very clear picture for users operating on budget laptops. Heavy artificial intelligence models simply do not make sense for older hardware. Bark and MeloTTS require excessive time and memory rendering them impractical for everyday deployment on a 4 GB VRAM graphics card.
While cloud engines like Edge TTS offer fast speeds they force reliance on external servers. For local CPU bound execution Piper TTS remains a strong candidate but it places significant stress on the processor.
The ultimate winner for this hardware category is Kokoro 82M. It provides the absolute best balance of speed and resource efficiency. By utilizing the lightweight ONNX runtime on the modest GTX 1650 it achieved rapid generation times of 225.8 characters per second without monopolizing system memory or maxing out the VRAM limits. It definitively proves that expensive workstations are not required to run powerful local synthesis. Kokoro 82M stands out as the single best text to speech engine capable of running on any low power laptop while generating amazing results.